7.3 Visualización de LLMs: Ver la IA por Dentro
Introducción
Hasta ahora hemos aprendido cómo se procesan las palabras (tokenización) y cómo se representan sus significados (embeddings). Pero, ¿qué sucede dentro de un modelo de lenguaje cuando genera una respuesta?
Imagina poder ver el interior de un cerebro artificial mientras piensa, ver cómo fluye la información a través de cada capa, cómo se transforman los vectores y cómo finalmente emerge una palabra predicha. Esto es exactamente lo que permite la visualización 3D interactiva de LLM creada por Brendan Bycroft.
Esta herramienta te permite explorar visualmente un modelo GPT pequeño, siguiendo paso a paso el viaje de un token desde la entrada hasta la salida generada.
¿Qué es un LLM?
Lo Esencial de los LLMs
Un Large Language Model (LLM) o Modelo de Lenguaje Grande es un tipo de IA que puede:
- Entender texto: Comprender el significado y contexto de lo que lee
- Generar texto: Crear respuestas coherentes y relevantes
- Aprender patrones: Identificar relaciones complejas en el lenguaje
- Predecir: Adivinar qué palabra viene después basándose en el contexto
¿Cómo funciona? El modelo procesa el texto a través de múltiples capas de transformación, donde cada capa refina la comprensión y añade más contexto. Es como pasar información por una cadena de especialistas, donde cada uno añade su perspectiva única.
La Visualización Interactiva de LLM
La herramienta de Brendan Bycroft (https://bbycroft.net/llm) ofrece una ventana única al funcionamiento interno de un modelo GPT. A diferencia de las explicaciones teóricas, aquí puedes ver y explorar cada componente en acción.
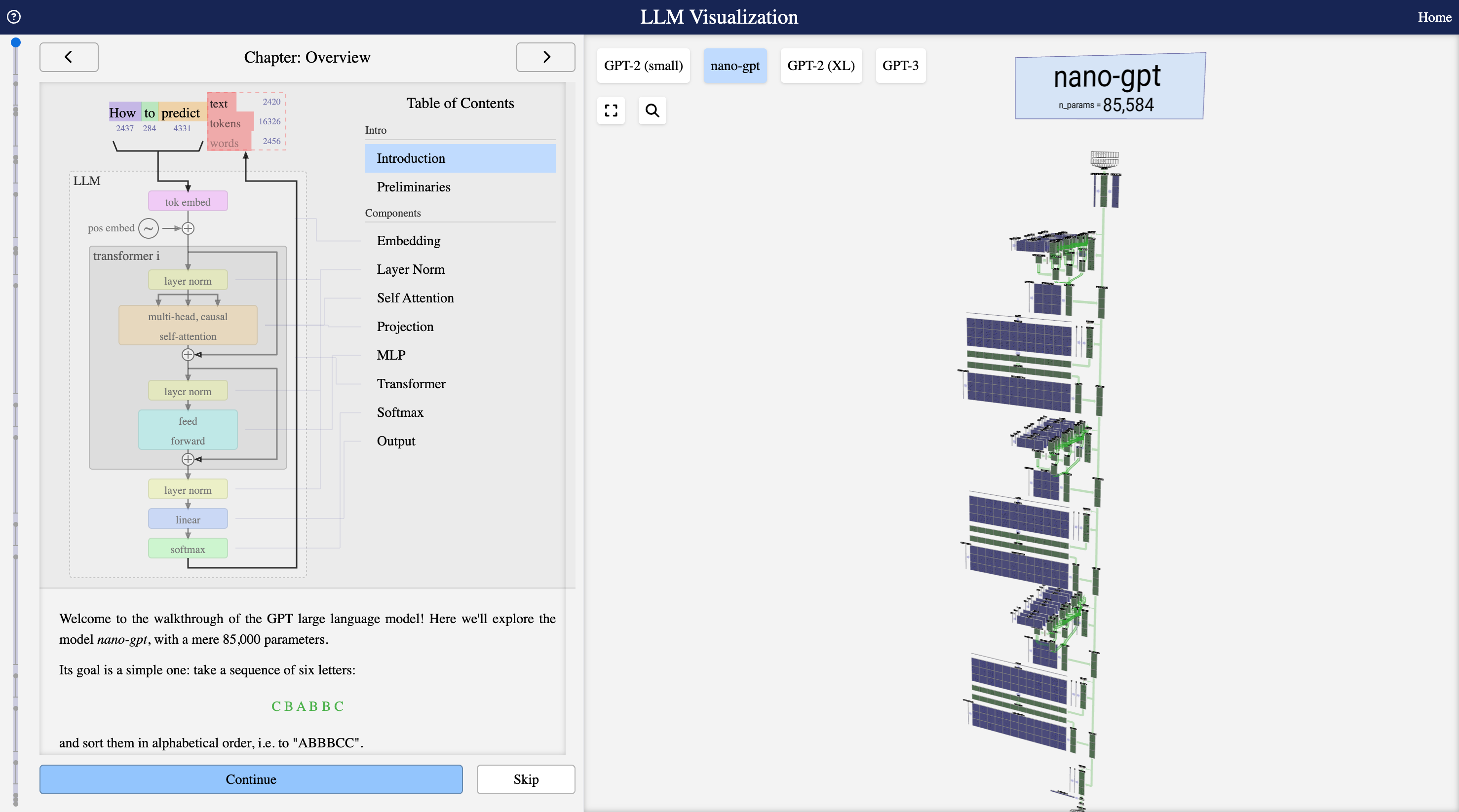
Figura: Visualización 3D de la arquitectura de un modelo de lenguaje grande. Puedes rotar, hacer zoom y explorar cada capa del modelo. Haz clic en la imagen para abrir la herramienta interactiva en bbycroft.net/llm.
¿Qué Puedes Ver en la Visualización?
Componentes Principales
1. Tokens de Entrada
- Ves cómo el texto se divide en tokens (como aprendimos en 7.1)
- Cada token se convierte en un vector de números
2. Embeddings
- Los tokens se transforman en embeddings (como vimos en 7.2)
- Puedes ver las dimensiones de estos vectores
3. Capas de Atención
- La parte más fascinante: el mecanismo de "atención"
- El modelo decide qué palabras son importantes para entender cada palabra
- Es como cuando lees una frase y prestas más atención a ciertas palabras clave
4. Capas de Transformación (Feed-Forward)
- Aquí es donde el modelo "piensa" y procesa la información
- Los vectores pasan por operaciones matemáticas complejas
- Cada capa refina la comprensión
5. Predicción Final
- Al final, el modelo genera probabilidades para cada palabra posible
- La palabra con mayor probabilidad es la que se elige como respuesta
El Mecanismo de Atención
El concepto más importante en los LLMs modernos es la atención (attention). Piensa en ello así:
Cuando lees la frase: "El paciente tiene diabetes y necesita insulina"
Tu cerebro automáticamente conecta:
- "diabetes" con "insulina" (tratamiento relacionado)
- "paciente" con "tiene" y "necesita" (sujeto de las acciones)
El mecanismo de atención hace exactamente esto: conecta palabras relacionadas para entender el contexto completo. En la visualización, puedes ver estas conexiones como líneas entre tokens.
Explora Cómo Funciona la Atención
En la herramienta interactiva, prueba lo siguiente:
- Escribe una frase médica: Por ejemplo, "The patient needs treatment"
- Observa las capas de atención: Verás líneas que conectan palabras relacionadas
- Sigue un token específico: Selecciona una palabra y observa cómo su representación cambia en cada capa
- Mira la predicción: Al final, el modelo sugiere qué palabra debería venir después
Nota: La visualización usa un modelo pequeño con propósitos educativos, no un LLM completo de producción.
De Tokens a Texto: El Viaje Completo
Ahora podemos conectar todo lo que hemos aprendido en el Capítulo 7:
El Pipeline Completo
Paso 1: Tokenización (7.1)
"El paciente tiene fiebre" → ["El", "paciente", "tiene", "fiebre"]Paso 2: Embeddings (7.2)
["El", "paciente", "tiene", "fiebre"] → [vector₁, vector₂, vector₃, vector₄]Paso 3: Procesamiento en Capas (7.3 - Esto que estamos viendo ahora)
- Los vectores pasan por múltiples capas de atención y transformación
- Cada capa refina la comprensión del contexto
- El modelo aprende relaciones complejas entre palabrasPaso 4: Predicción
El modelo predice la siguiente palabra: "alta" (probabilidad 0.85)
Frase completa: "El paciente tiene fiebre alta"Referencias y Recursos Adicionales
- LLM Visualization (Interactive) - Exploración 3D interactiva de arquitecturas de transformers
- The Illustrated Transformer - Explicación visual detallada de la arquitectura transformer
- Attention is All You Need (Paper Original) - El paper que introdujo el mecanismo de atención